
Most CRM deduplication tools are built on a simple premise: if two records share the same email address, they are likely the same contact. Flag them, merge them, move on.
The logic is not wrong. It is just incomplete.
The problem is that many duplicate contacts in HubSpot and Pipedrive do not share an email address. They were entered through different channels, at different times, by different people — and each entry captured different information. No shared email means no match, and no match means no flag.
Exact-match deduplication handles the easy cases. Fuzzy matching CRM tools handle the rest.
What Is Exact-Match Deduplication?
Exact-match deduplication works exactly as the name suggests: two records are identified as potential duplicates only when a specific field — usually email address — is character-for-character identical across both.
HubSpot's native duplicate detection is primarily exact-match. Pipedrive's built-in tool also relies heavily on exact name and organisation matching.
This approach works well when:
- A contact submits the same form twice using the same email
- A rep manually enters a contact whose email already exists in the CRM
It fails when:
- A contact uses two different email addresses (personal vs work)
- One record has an email; the other was entered with only a LinkedIn URL
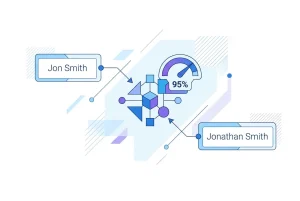
- A name is abbreviated on one record ("J. Smith") and written in full on another ("Jonathan Smith")
- Two records share a mobile number but no other overlapping field
In all of these cases, exact-match logic sees two separate contacts. Your CRM now holds duplicates it will never flag.
How Fuzzy Matching CRM Tools Work
Fuzzy matching is a technique that identifies similarity between data points rather than requiring an exact character match. Rather than asking "are these two strings identical?", fuzzy matching asks "how similar are these two strings — and is that similarity close enough to indicate the same entity?"
In the context of CRM deduplication, fuzzy matching compares contact records across multiple fields simultaneously, scoring each comparison to produce a confidence level.
A basic fuzzy match might use an algorithm like Levenshtein distance — measuring how many character edits are needed to turn one string into another — to determine whether "Jon" and "Jonathan" are likely the same person. More sophisticated approaches use AI-based models trained on contact data, which can reason about combinations of fields rather than evaluating each field in isolation.
The key difference from exact matching is this: fuzzy matching does not need a single field to match perfectly. It looks at the whole picture.
Why Exact-Match Misses More Than You Think
Consider a practical example that plays out regularly in any active CRM:
**Record A**
- Name: David Park
- Email: [email protected]
- Company: Global Ops
- LinkedIn URL: *(blank)*
**Record B**
- Name: Dave Park
- Email: *(blank)*
- Company: Global Ops
- LinkedIn URL: linkedin.com/in/davidpark
- Mobile: +44 7800 654321
Exact-match deduplication looks at these and sees two different contacts. There is no shared email. The names are different. Case closed.
A fuzzy matching CRM tool looks at these and asks: same company, near-identical name, LinkedIn URL is present on one and absent from the other — and a mobile number that could confirm identity if cross-referenced elsewhere. The confidence score comes back high. These records are flagged as a likely duplicate pair.
The difference is not just a technical detail. In a database of 10,000 contacts, the records that exact-match catches are a fraction of the actual duplicates present. Research consistently shows that between 10% and 30% of CRM records are duplicates or contain significant errors — and exact-match tools surface only a portion of them.
How AI Matching Goes Beyond Fuzzy
Fuzzy matching is a significant step forward from exact matching, but it still operates primarily at the field level. An AI-based matching approach goes further by reasoning across fields together.
[EazyMatch AI](https://datamadeeazy.com/eazymatch-ai/) uses multi-field AI matching to identify duplicate contacts and companies in HubSpot and Pipedrive. Rather than scoring each field independently, it evaluates the combination:
- **Email address** — including partial matches and domain variants
- **Similar name within the same company** — a name variant at the same organisation is a strong signal
- **Partial name match** — catches abbreviations and common informal variants
- **LinkedIn URL** — a unique professional identifier; shared across two records means same person
- **Mobile number** — mobile numbers are highly stable identifiers and rarely shared between contacts
For companies, EazyMatch AI matches on the LinkedIn company URL and website domain.
Why This Matters for Your Pipeline
Duplicate contacts are not just a data hygiene issue. They have direct commercial consequences:
- **Segmentation breaks** — contacts split across two records may fall into different list segments, skewing your targeting and personalisation
- **Double outreach** — sales reps work the same prospect simultaneously without knowing it, creating a poor experience and wasted effort
- **Reporting inaccuracy** — conversion rates, pipeline values, and attribution figures are all distorted when the same person appears as multiple contacts
- **Automation failures** — workflows triggered on contact properties may fire twice, or not at all, because the relevant data is split across two records
Fixing these problems starts with finding the duplicates — including those that exact-match logic cannot detect.
The result is that a record pair like David Park and Dave Park at Global Ops — with a shared LinkedIn URL on one side — gets flagged with high confidence, even without a shared email. That is the class of duplicate that exact-match deduplication will never surface.
FAQ
Q: Is fuzzy matching accurate enough to trust for CRM deduplication?
Modern AI-based fuzzy matching is highly accurate when it evaluates multiple fields together rather than relying on a single similarity score. EazyMatch AI assigns a confidence score to each flagged pair and surfaces the matched fields so you can see exactly why two records were identified as potential duplicates. Every suggestion requires human review before any changes are made in your CRM.
Q: Will fuzzy matching flag false positives — two different people with similar names?
It can, which is why confidence scoring and human review are essential parts of any deduplication workflow. EazyMatch AI presents each flagged pair for approval and shows you the specific fields that drove the match — so you can dismiss a false positive (two different "J. Smiths" at the same company, for example) without merging records that should stay separate.
Q: Does EazyMatch AI work with both HubSpot and Pipedrive?
Yes. EazyMatch AI connects directly to HubSpot and Pipedrive and applies the same multi-field AI matching logic to both. You can run deduplication checks on either CRM or both from a single account.
The Duplicates Worth Finding
Exact-match deduplication solves a small part of the problem. Fuzzy matching CRM tools and AI-based contact matching solve the rest— catching the contacts with different email addresses, abbreviated names, and LinkedIn URLs that share no single identical field but are clearly the same person.
Most CRM portals contain far more of these than their teams realise.
If you're evaluating tools to address these gaps, see "why teams switch from Dedupely to EazyMatch AI "


